








Choose the Right Database for Your Application
November 28, 2017
Databases are key components of many an app and choosing the right option is an elaborate process. This article examines the role that databases play in apps, giving readers tips on selecting the right option. It also discusses the pros and cons of a few select databases.
Every other day we discover a new online application that tries to make our lives more convenient. And as soon as we get to know about it, we register ourselves for that application without giving it a second thought. After the one-time registration, whenever we want to use that app again, we just need to log in with our user name and password —the app or system automatically remembers all our data that was provided during the registration process. Ever wondered how a system is able to identify us and recollect all our data on the basis of just a user name and password? It’s all because of the database in which all our information or data gets stored when we register for any application.
Similarly, when we browse through millions of product items available on various online shopping applications like Amazon, or post our selfies on Facebook to let all our friends see them, it’s the database that is making all this possible.
According to Wikipedia, a database is an organised collection of data. Now, why does data need to be in an organised form? Let’s flash back to a few years ago, when we didn’t have any database and government offices like electricity boards stored large heaps of files containing the data of all users. Imagine how cumbersome it must have been to enter details pertaining to a customer’s consumption of electricity, payments made or pending, etc, if the names were not listed alphabetically. It would have been time consuming as well. It’s the same with databases. If the data is not present in an organised form, then the processing time in fetching any data is quite long. The data stored in a database can be in any organised form—schemas, reports, tables, views or any other objects. These are basically organised in such way as to help easy retrieval of information. The data stored in files can get lost when the papers of these files get older and, hence, get destroyed. But in a database, we can store data for millions of years without any such fear. Data will get lost only when the system crashes, which is why we keep a backup.
Now, let’s have a look at why any application needs a database.
- It will be difficult for any online app to store huge amounts of data for millions of its customers without a database.
- Apart from storing data, a database makes it quite easy to update any specific data (out of a large volume of data already residing in the database) with newer data.
- The data stored in a database of an app will be much more secure than if it’s stored in any other form.
- A database helps us easily identify any duplicate set of data present in it. It will be quite difficult to do this in any other data storage method.
- There is the possibility of users entering incomplete sets of data, which can add to the problems of any application. All such cases can be easily identified by any database.
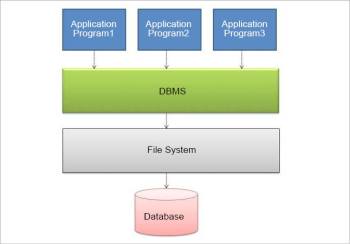
A user cannot directly interact with any database—there needs to be an interface or intermediate system, which helps the user to interact with it. Such an interface is referred to as a database management system (DBMS). It is basically a computer software application that interacts with the user or other applications, and even with the database itself, in order to capture and analyse the data. Any DBMS such as MySQL is designed in such a way that it allows the definition, querying, creation, updation and administration of the whole database. It is where we request the database to give us the required data in the query language.
Different types of databases
Relational database: This is one of the most common of all the different types of available databases. In such types of databases, the data is stored in the form of data tables. Each table has a unique key field, which is used to connect it to other tables. Therefore, all the tables are related to each other with the help of several key fields. These databases are used extensively in different industries and will be the type we are most likely to come across when working in IT.
Operational database: An operational database is quite important for organisations. It includes the personal database, customer database and inventory database, all of which cover details of how much of any product the company has, as well as the information on the customers who buy the products. The data stored in different operational databases can be changed and manipulated based on what the company requires.
Data warehouses:Many organisations are required to keep all relevant data for several years. This data is also important for analysing and comparing the present year data with that of the previous year, to determine key trends. All such data, collected over years, is stored in a large data warehouse. As the stored data has gone through different kinds of editing, screening and integration, it does not require any more editing or alteration.
Distributed databases:Many organisations have several office locations—regional offices, manufacturing plants, branch offices and a head office. Each of these workgroups may have their own set of databases, which together will form the main database of the company. This is known as a distributed database.
End user databases:There is a variety of data available at the workstation of all the end users of an organisation. Each workstation acts like a small database in itself, which includes data in presentations, spreadsheets, Word files, downloaded files and Notepad files.

Choosing the right database for your application
Choosing the right database for an application is actually a long-term decision, since making any changes at a later point can be difficult and even quite expensive. So, we cannot even afford to go wrong the first time. Let’s see what benefits we will get if we choose the right database the first time itself.
- Only if we choose the right database will the relevant and the required information get stored in the database, putting data in a consistent form.
- It’s always preferable that the database design is normalised. It helps to reduce data redundancy and even prevents duplication of data. This ultimately leads to reducing the size of the database.
- If we choose the correct database, then the queries fired in order to fetch data will be simple and will get executed faster.
- The overall performance of the application will be quite good.
- Choosing the right database for an application also helps in easy maintenance.
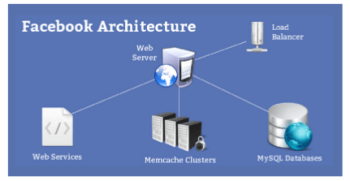
Factors to be considered while choosing the right database for your application
Well, there is a difference between choosing any database for an application and choosing the right database for it. Let’s have a look at some of the important factors to be considered while choosing a database for an application.
Structure of data: The structure of the data basically decides how we need to store and retrieve it. As our applications deal with data present in a variety of formats, selecting the right database should include picking the right data structures for storing and retrieving the data. If we do not select the right data structures for persisting our data, our application will take more time to retrieve data from the database, and will also require more development efforts to work around any data issues.
Size of data to be stored: This factor takes into consideration the quantity of data we need to store and retrieve as critical application data. The amount of data we can store and retrieve may vary depending on a combination of the data structure selected, the ability of the database to differentiate data across multiple file systems and servers, and even vendor-specific optimisations. So we need to choose our database keeping in mind the overall volume of data generated by the application at any specific time and also the size of data to be retrieved from the database.
Speed and scalability: This decides the speed we require for reading the data from the database and writing the data to the database. It addresses the time taken to service all incoming reads and writes to our application. Some databases are actually designed to optimise read-heavy applications, while others are designed in a way to support write-heavy solutions. Selecting a database that can handle our application’s input/output needs can actually go a long way to making a scalable architecture.
Accessibility of data: The number of people or users concurrently accessing the database and the level of computation involved in accessing any specific data are also important factors to consider while choosing the right database. The processing speed of the application gets affected if the database chosen is not good enough to handle large loads.
Data modelling:This helps map our application’s features into the data structure and we will need to implement the same. Starting with a conceptual model, we can identify the entities, their associated attributes, and the entity relationships that we will need. As we go through the process, the type of data structures we will need in order to implement the application will become more apparent. We can then use these structural considerations to select the right category of database that will serve our application the best.
Scope for multiple databases:During the modelling process, we may realise that we need to store our data in a specific data structure, where certain queries cannot be optimised fully. This may be because of various reasons such as some complex search requirements, the need for robust reporting capabilities, or the requirement for a data pipeline to accept and analyse the incoming data. In all such situations, more than one type of database may be required for our application. When choosing more than one database, it’s quite important to select one database that will own any specific set of data. This database acts as the canonical database for those entities. Any additional databases that work with this same set of data may have a copy, but will not be considered as the owner of this data.
Safety and security of data: We should also check the level of security that any database provides to the data stored in it. In scenarios where the data to be stored is highly confidential, we need to have a highly secured database. The safety measures implemented by the database in case of any system crash or failure is quite a significant factor to keep in mind while choosing a database.
A few open source database solutions available in the market
MySQL
MySQL has been around since 1995 and is now owned by Oracle. Apart from its open source version, there are also different paid editions available that offer some additional features, like automatic scaling and cluster geo-replication. We know that MySQL is an industry standard now, as it’s compatible with just about every operating system and is written in both C and C++. This database solution is a great option for different international users, as the server can provide different error messages to clients in multiple languages, encompassing support for several different character sets.
Pros
- It can be used even when there is no network available.
- It has a flexible privilege and password system.
- It uses host-based verification.
- It has security encryption for all the password traffic.
- It consists of libraries that can be embedded into different standalone applications.
- It provides the server as a separate program for a client/server networked environment.
Cons
- Different members are unable to fix bugs and craft patches.
- Users feel that MySQL no longer falls under the category of a free OS.
- It’s no longer community driven.
- It lags behind others due to its slow updates.
SQLite
SQLite is supposedly one of the most widely deployed databases in the world. It was developed in 2000 and, since then, it has been used by companies like Facebook, Apple, Microsoft and Google. Each of its releases is carefully tested in order to ensure reliability. Even if there are any bugs, the developers of SQLite are quite honest about the potential shortcomings by providing bug lists and the chronologies of different code changes for every release.
Pros
- It has no separate server process.
- The file format used is cross-platform.
- It has a compact library, which runs faster even with more memory.
- All its transactions are ACID compliant.
- Professional support is also available for this database.
Cons
It’s not recommended for:
- Different client/server applications.
All high-volume websites.
- High concurrency.
- Large datasets.
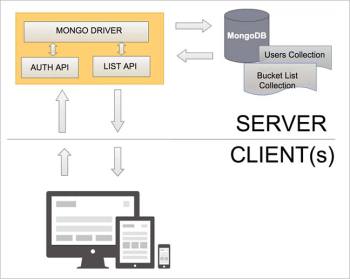
MongoDB
MongoDB was developed in 2007 and is well-known as the ‘database for giant ideas.’ It was developed by the people behind ShopWiki, DoubleClick, and Gilt Group. MongoDB is also backed by a large group of popular investors such as The Goldman Sachs Group Inc., Fidelity Investments, and Intel Capital. Since its inception, MongoDB has been downloaded over 15 million times and is supported by more than 1,000 partners. All its partners are dedicated to keeping this free and open source solution’s code and database simple and natural.
Pros
- It has an encrypted storage engine.
- It enables validation of documents.
- Common use cases are mobile apps, catalogues, etc.
- It has real-time apps with an in-memory storage engine (beta).
- It reduces the time between primary failure and recovery.
Cons
- It doesn’t fit applications which need complex transactions.
- It’s not a drop-in replacement for different legacy applications.
- It’s a young solution—its software changes and evolves quickly.
MariaDB
MariaDB has been developed by the original developers of MySQL. It is widely used by tech giants like Facebook, Wikipedia and even Google. It’s a database server that offers drop-in replacement functionality for MySQL. Security is one of the topmost concerns and priorities for MariaDB developers, and in each of its releases, the developers also merge in all of MySQL’s security patches, even enhancing them if required.
Pros
- It has high scalability with easier integration.
- It provides real-time access to data.
- It has the maximum core functionalities of MySQL (MariaDB is an alternative for MySQL).
- It has alternate storage engines, patches and server optimisations.
Cons
- Password complexity plugin is missing.
- It does not support the Memcached interface.
- It has no optimiser trace.









Recommended