Digital Brains, Financial Backbone: Building ML for FinTech Integrity
May 27, 2025
Introduction
In today’s high-stakes financial landscape, machine learning is fast becoming the cornerstone of intelligent fraud prevention. As threats evolve from deceptive social engineering ploys to stealthy account takeovers financial institutions face growing pressure to stay ahead. Static rule-based systems falter under this complexity, but dynamic ML models rise to the challenge. By detecting patterns in real time whether it’s payment fraud, identity theft, or suspicious user activity these models do more than just react; they anticipate. Crucially, they align with key business imperatives: minimizing losses, streamlining operations, and upholding regulatory trust.
Financial institutions must bridge the gap between data scientists and business operations in order to develop effective fraud detection tools. Technical teams, compliance officers, and fraud detectives must work together across functional boundaries. Organizations can only guarantee the accuracy, security, and regulatory readiness of their fraud detection systems when technical solutions are in line with business objectives.
Administrators, statisticians, regulatory teams, and technology executives in the banking and finance sector are the target audience for this blog. It looks at how to create complete machine learning systems that are secure, comprehensible, and comply with regulations in addition to being accurate and scalable. It seeks to offer practical ideas for creating robust fraud detection solutions, covering everything from managing data to real-time installation, post-deployment tracking, and emerging trends.
Challenges of Building Secure, Compliant Machine Learning Systems
One of the most significant obstacles is enabling financial institutions to develop secure, lawful intelligent systems for fraud detection. To protect user identities, identity verification records, and financial information, these systems must have robust security features including encoding, multi-factor authentication, and encrypted data intake pipelines. New fraud trends including social media scams, money laundering, and synthetic identities require frequent model training and adaptable feature engineering to stay up with evolving fraudulent activities. Unlike traditional rule-based systems, modern machine learning models must proactively detect strange patterns and minimize false alarms to maintain trust and improve operational efficiency.
Regulatory conformance introduces another level of complexity by requiring that models be transparent, explicable, and consistent with privacy regulations, especially when managing sensitive transaction data and identifying potential fraud. Explainable AI is crucial for protecting detected financial activity and supporting further investigation by identifying fraud and compliance teams.
Controlling the quantity and quality of input data used to train machine learning algorithms is another crucial difficulty. Well-labeled historical data that reflects both authentic users and questionable activity, such as identity theft, institution takeover, and money laundering, is essential for accurate fraud detection. The detection of possible fraud may be directly impacted by models that overfit, perform poorly, or fail to lower false positives as a consequence of poor data management.
In addition, business KPIs like avoiding financial losses, enhanced customer satisfaction, and less disturbance to actual customers must be included in model evaluation in addition to technical performance measures. As financial institutions use tensor processing machines for deep learning instruction and deploy complicated models in safe settings like Google Cloud, it is crucial to make sure that model performance stays constant and in line with predetermined baselines.
In the high-risk digital environment of today, combating fraud at scale demands keeping the equilibrium between model accuracy, agility, and operational openness.
Data Strategy & Governance
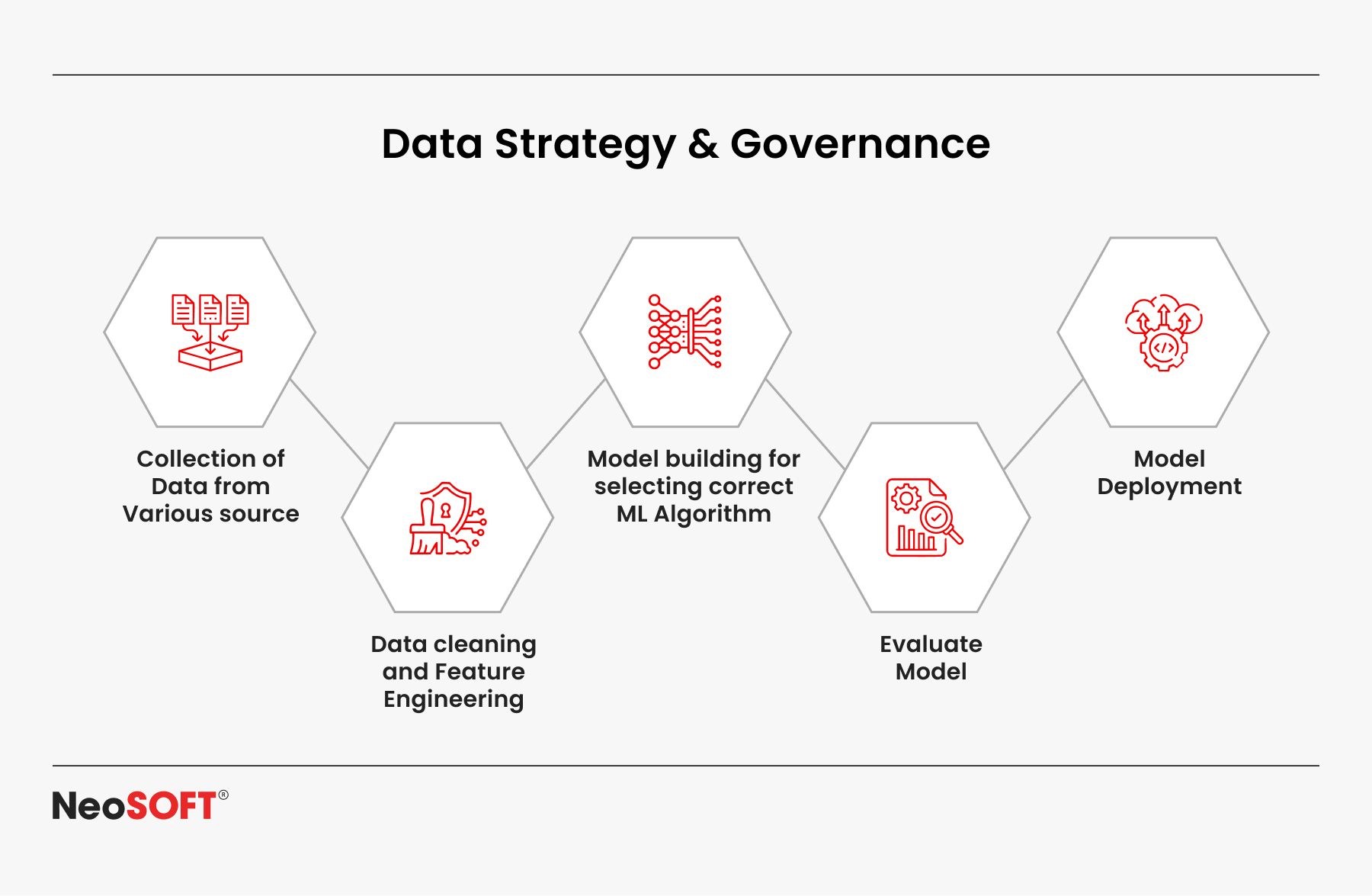
Proper handling of information is the first step in creating a machine learning system that is both secure and scalable. Big datasets of transactions, including confidential information like transaction records and identity verification, are handled by financial institutions. This financial information needs to be safeguarded by anonymity, encryption, and accessibility restrictions in order to stop fraud and guarantee adherence to laws like GDPR and PCI DSS.
Through allowing financial institutions to track each forecast or financial transaction generated by machine learning models, maintaining data lineage through audit records promotes transparency. This is particularly crucial for real-time activity monitoring, as anomaly identification and odd trends could lead fraud investigators to look into the matter further.
High-quality input data is also essential to a reliable fraud detection system. For model training to be successful, labeled historical data that records both authentic consumer behavior and fraudulent activity, which includes theft of identities, payment fraud, or account takeover, is essential. It facilitates pattern recognition, lowers false positives, and improves the precision of risk score assignment for machine learning algorithms.
As a way to enable data scientists identify important signals in unprocessed transactional data, feature engineering is essential. These characteristics support deep learning models, which increase operational effectiveness and predictive capacity. Built in environments such as Google Cloud, secure data input pipelines guard against violations, data poisoning, and model drift while supporting scalable machine learning architecture.
In the long run, a well-managed data strategy preserves client confidence while improving fraud protection. It ensures that trustworthy data is used to train machine learning models, reducing false positives, promoting compliance, and bolstering fraud control through the infrastructure.
Model Development & Validation
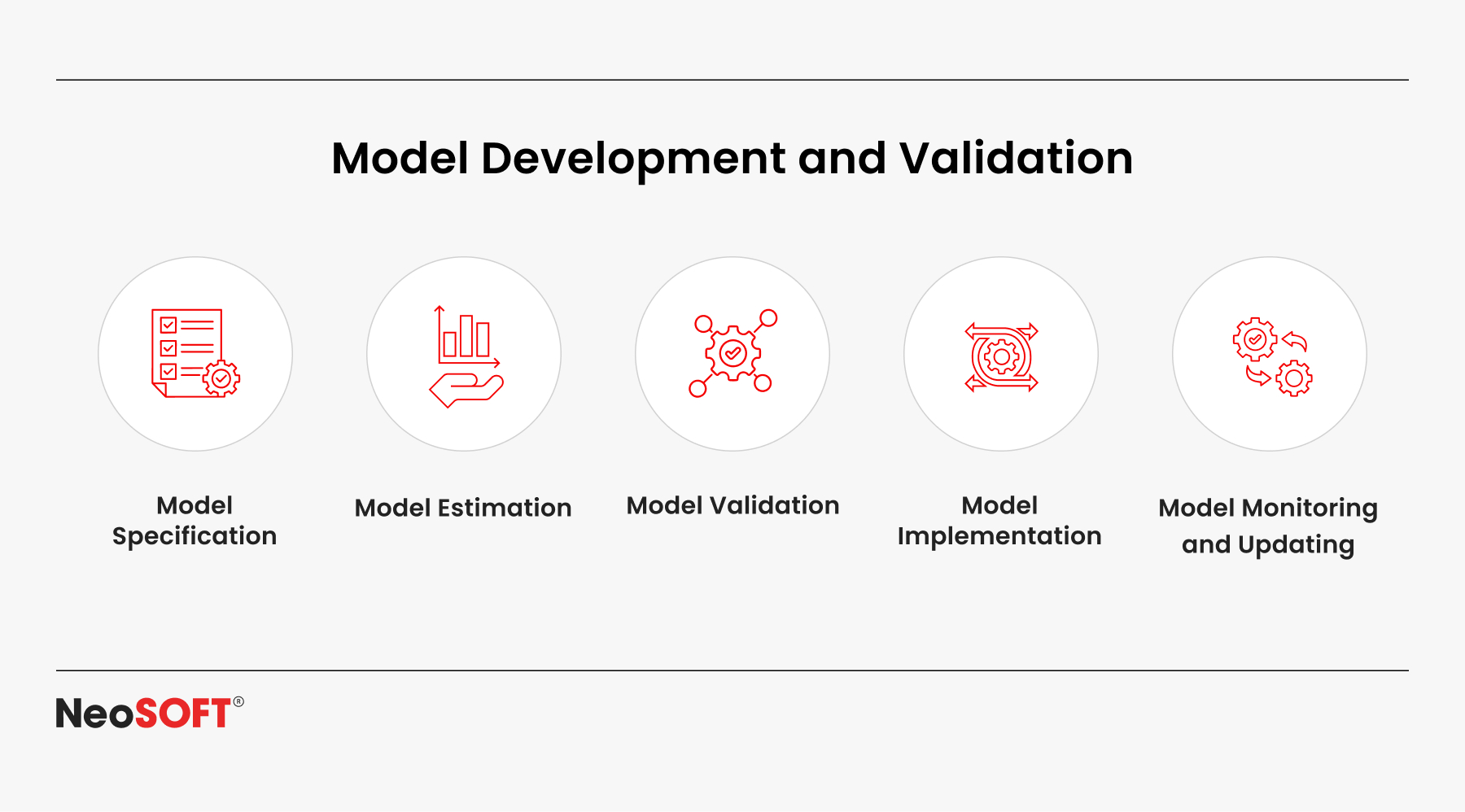
Picking the appropriate neural network architectures is essential for any application in finance. Forecast strength, model simplicity, and the capacity to apply anomaly detection to spot potential fraud are some of the variables that influence the model selection. Performance and transparency must be balanced by financial institutions, particularly in high-risk sectors like money laundering and detection of fraud.
Establishing sure the models are complying with regulations involves integrating explainable artificial intelligence (XAI) technologies into the model building process. Model developers can use these techniques to find patterns that may be important for reporting and fraud detection. Stress-testing equations for partiality and adaptability before putting them to use in a real-world setting is another step in the validation process.
Technical metrics for performance and commercial objectives, such as decrease in error rates and a boost in the accuracy of fraud detection, should also be considered when evaluating the model. Model drift or a decline in performance over the years can be detected by tracking the parameters associated with the model while contrasting them to earlier baselines.
Secure ML Infrastructure
Constructing a machine learning system that’s efficient requires a strong, safe architecture that prioritizes security. To safeguard data intake pipelines and guarantee the secure implementation of machine learning models, financial institutions need to implement cloud-native platforms like Google Cloud Platform and AWS IAM, which offer sophisticated functionalities. Such systems provide secure data storage, data encryption, and fine-grained access control, which makes it simpler to adhere to legal requirements and protect private financial information.
It’s also vital to safeguard the computational learning models themselves. Prediction accuracy can be severely impacted by conflicting attacks and data poisoning, making computations susceptible to manipulation. To reduce these risks, financial institutions need to use techniques like anomaly detection, model hardening, and ongoing monitoring. Furthermore, using models developed with deep learning on specialized hardware, such as tensor processing units (TPUs), can effectively handle the growing computing needs as financial data becomes more complex. TPUs speed up training procedures and guarantee that deep learning algorithms function properly at magnitude, even as the amount of data increases.
The flexible nature of system components is a crucial factor in safe machine learning infrastructure. Machine learning models may be seamlessly integrated with old or current systems by creating infrastructure that is adaptable and modular. This strategy guarantees that new models for identity verification, fraud detection, and various other safety protocols can be implemented without interfering with the present operations of the company. Also, modular designs preserve system scalability, which facilitates adaptation to future expansion, new fraud trends, and changing business requirements.
Financial organizations may build a safe, scalable AI environment that can handle sensitive data while preserving the performance needed for immediate fraud identification and risk management by giving priority to these design concepts.
Compliance-Driven MLOps
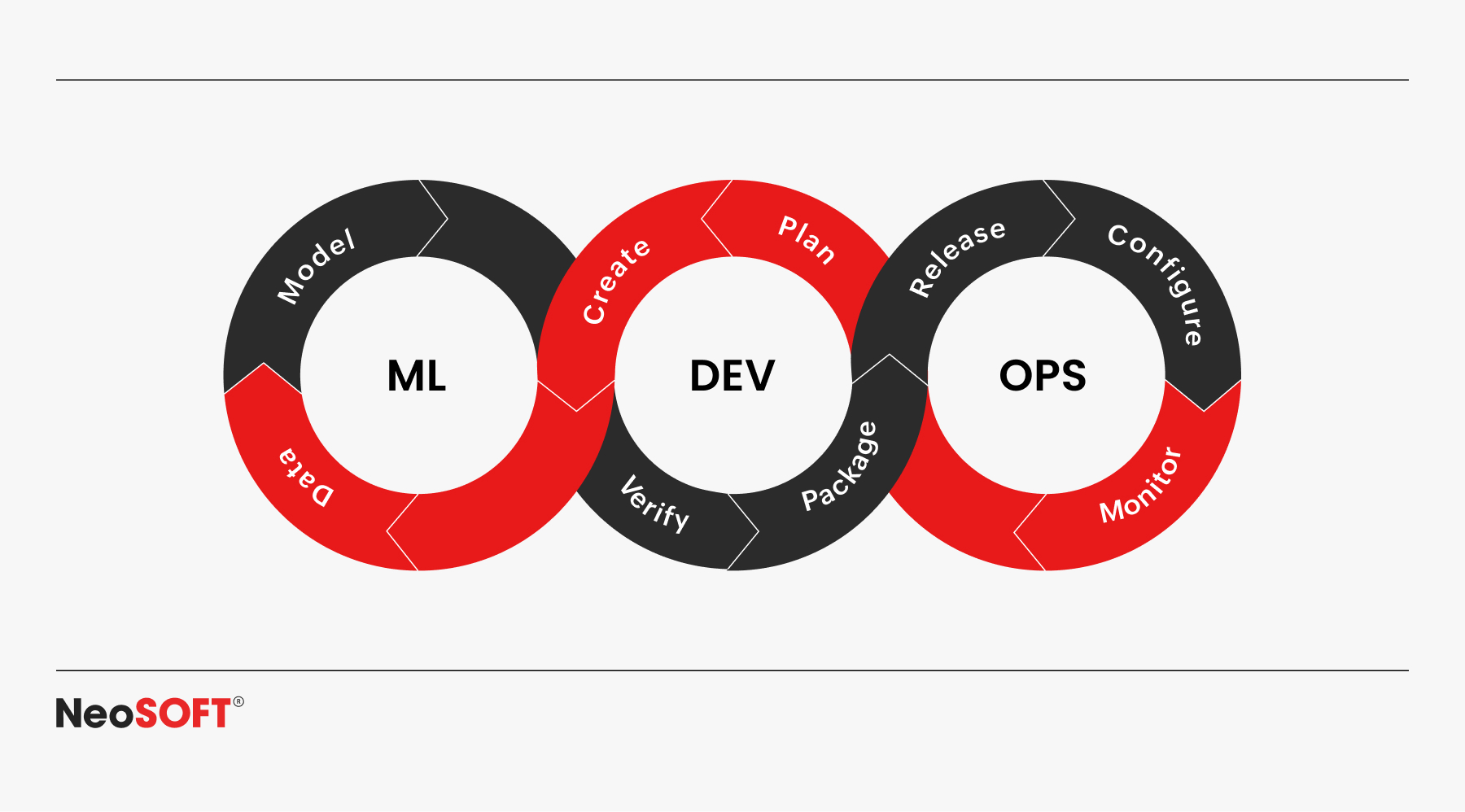
With compliance-as-code, embedding governance into CI/CD workflows for ML systems ensures every step from model training to deployment adheres to regulatory compliance. This is important for financial organizations handling confidential transaction data, identity verification, and fraud prevention.
Through recognizing bias, drift, and fairness problems early on, real-time model monitoring allows for quick action before operational breakdowns or compliance violations take place. In fraud detection, this ensures models analyzing incoming data and financial transactions remain accurate and aligned with emerging fraud patterns and normal behavior.
Audit logs of all production decisions create transparency critical in sectors handling payment fraud, identity theft, and money laundering. These logs support further investigation into suspicious activities and provide insight into how machine learning algorithms assign risk scores.
Fraud investigators’ expertise should also be incorporated into MLOps workflows in order to improve models in response to fresh fraud indicators. Reducing false positives and adjusting to new fraud patterns are made easier by combining past information, identifying anomalies, and user behavior analysis.
In the end, compliance-driven MLOps increase operational efficiency through the integration of artificial intelligence infrastructure with current systems, enabling systems that use rules and deep learning models to guard against fraud while safeguarding legitimate clients.
Real-Time & Scalable Deployment
Serving the models at scale with a short latency becomes the top priority when they have been validated and are ready for deployment. To identify fraudulent activity and minimize financial losses, financial institutions need to handle enormous amounts of entering data in real-time. In order to stop fraudulent transactions before transactions are finished, speed is essential.
Low-latency, scalable deployments are made possible by technologies such as event-driven systems, orchestration, and containers. These facilitate the seamless detection of fraud across settings without interfering with essential services through combining predictive modeling infrastructure with present technologies.
Additionally, real-time transaction data monitoring across infrastructure components is made possible by scalable systems. This improves the efficiency of operations and customer experience by guaranteeing availability, auto-scaling, and supporting preemptive identification of anomalies, payment fraud protection, and decreasing false positives.
Post-deployment, institutions must track model performance using historical data and performance metrics. Monitoring helps detect drift, supports retraining to respond to emerging fraud trends, and ensures continued accuracy and protection for legitimate users.
Post-Deployment Monitoring & Governance
Machine learning systems need to be continuously monitored after deployment to make sure they are operating as planned and not deviating from usual conduct. Financial firms can assess the model’s effectiveness and link it to financial goals, such as bettering customer experience or preventing fraud, by monitoring key performance indicators (KPIs).
Furthermore, human-in-the-loop solutions prove essential for compliance-sensitive choices because they enable fraud investigators to examine possible fraudulent activity that the system has detected before taking any further action. Dashboards supporting governance can be utilized to monitor system health and swiftly escalate anomalies.
Adapting to shifting fraud strategies involves constant model examination and retraining using new input data. This assures the models’ permanent high predicted accuracy and their ability to effectively spot new fraud trends.
To strengthen this phase, financial institutions should establish feedback loops between fraud investigators and data scientists. Subsequent feature engineering and model training are informed by these loops, which increase the detection of payment fraud, account takeover, and identity theft. Drift can be identified early and alignment with baselines can be maintained using actual time surveillance of model variables along with performance metrics.
Automated alerts, audit trails, and scalable cloud-based infrastructure like Google Cloud further enhance anomaly detection, ensure regulatory compliance, and support real-time transaction monitoring without compromising operational efficiency.
Conclusion
It is obvious that creating robust,scalable, and efficient technology is critical as artificial intelligence keeps changing the financial services industry. Financial firms are under increasing pressure to process vast volumes of transaction data in real time, identify possible fraudulent activity, and comply with complex legal requirements. The strong machine learning architecture in this environment needs to be beyond mere automation. In order to guarantee that judgments can be comprehended and confirmed, it should be proactive in spotting odd trends, transparent to encourage accountability and compliance, and explainable.
Institutions could stay on top of fraudsters by utilizing cutting-edge machine learning technology, incorporating feedback chains from fraud detectives, and implementing models that adjust to new data and changing threats. To preserve optimal model performance and minimize false positives, these systems must integrate effortlessly with current infrastructure, use deep learning training as necessary, and constantly improve through MLOps methods.
To guarantee long-term resilience, organizations need to evaluate their present ML readiness, modernize old infrastructures, and adopt MLOps best practices. Financial organizations can strike an equilibrium amongst security, compliance, and client trust by using the appropriate solutions.
Allow us to assist you in making your systems future-proof by identifying fraud. Contact us at info@neosofttech.com on how our artificial intelligence-powered offerings can give your financial institution the protection, compliance, and scalability it requires.

Up Next
Enterprise AI Adoption: The Gap Between Using AI and Running on AI Is Where Most Companies Will Lose

Up Next
Still Processing Claims Manually? Why Insurance Claims Automation Is Transforming the Industry