There has been a lot of noise recently about terms like “bitcoin,” “blockchain,” and “cryptocurrency.” Some of it is hype, but some of it points to important forces in the financial services industry. So what does it all mean?
We can help. We’ve pulled together a few short articles that explain why a lot of industry observers are paying close attention.
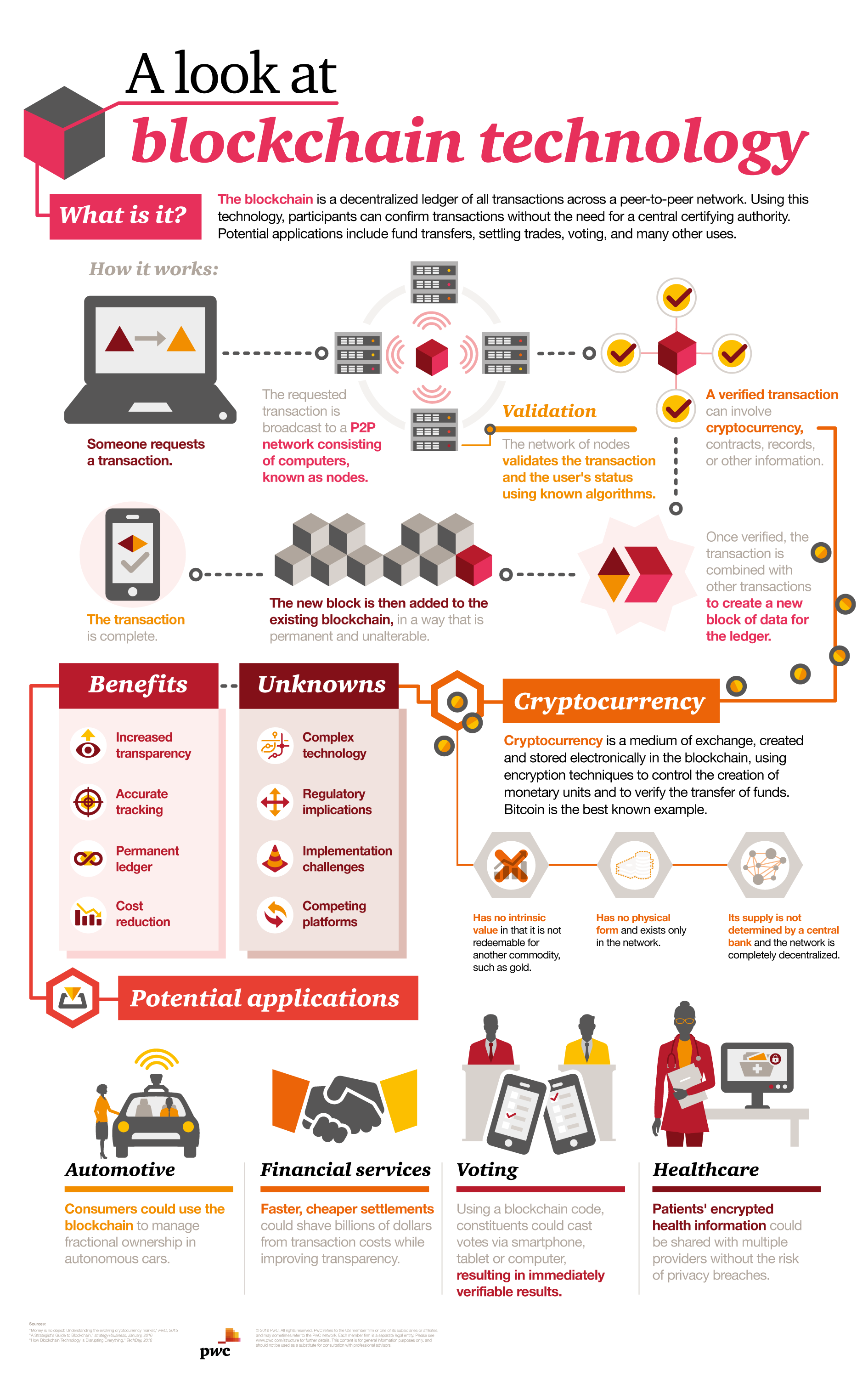
Let’s start with some quick definitions. Blockchain is the technology that enables the existence of cryptocurrency (among other things). Bitcoin is the name of the best-known cryptocurrency, the one for which blockchain technology was invented. A cryptocurrency is a medium of exchange, such as the US dollar, but is digital and uses encryption techniques to control the creation of monetary units and to verify the transfer of funds.
Blockchain also has potential applications far beyond bitcoin and cryptocurrency. Blockchain is, quite simply, a digital, decentralized ledger that keeps a record of all transactions that take place across a peer-to-peer network. The major innovation is that the technology allows market participants to transfer assets across the Internet without the need for a centralized third party.
From a business perspective, it’s helpful to think of blockchain technology as a type of next-generation business process improvement software. Collaborative technology, such as blockchain, promises the ability to improve the business processes that occur between companies, radically lowering the “cost of trust.” For this reason, it may offer significantly higher returns for each investment dollar spent than most traditional internal investments.
Financial institutions are exploring how they could also use blockchain technology to upend everything from clearing and settlement to insurance.
For an overview of cryptocurrency, start with “Money is no object.” This paper, from PwC’s Financial Services Institute, focuses on cryptocurrency. We explain where it came from, how much consumers know about it and use it, what it will take for the market to grow, and what the regulators think. We also look at how market participants, such as investors, technology providers, and financial institutions, will be affected.
For some quick background on blockchain, take a look at “What is blockchain?” This short article provides some examples of the innovative uses of blockchain already being implemented by financial institutions. It also provides an overview of the challenges and opportunities that blockchain presents for the industry.
For a look at blockchain’s future, peer into our crystal ball with “What’s next for blockchain in 2016?” This short article discusses the trends that will shape how blockchain technology will be used and developed. From financial institutions needing to think about protecting their intellectual property to a shakeout in venture capital funding, this will be a busy year.
For a deeper dive into blockchain’s implications, read “A strategist’s guide to blockchain.” This article, fromstrategy+business, examines the potential benefits of this important innovation — and also suggests a way forward for financial institutions. Put simply, proceed deliberately. Explore how others might try to disrupt your business with blockchain technology, and how your company could use it to leap ahead instead. In all cases, link your investments to your value proposition, and give your business partners and your customers what they want most: speed, convenience, and control over their transactions.
For a peek into the application of blockchains for smart contracts, check out “Blockchain and smart contract automation”. This short series of articles explore how blockchains, both public and private, have triggered a global hunt for ways to remove friction from transaction-related processes, including the process of reaching contractual agreements. Learn about the precursors, challenges, and future outlook of implementing smart contracts. We also chat with Gideon Greenspan of Coin Sciences to learn about his views on the legal ramifications of public blockchains and why companies are seeking alternatives.
When a technology moves so quickly, it’s dangerous to sit on the sidelines. We’re watching blockchain move from a startup idea to an established technology in a tiny fraction of the time it took for the Internet or even the PC to be accepted as a standard tool. Blockchain technology could result in a radically different competitive future for the financial services industry. These articles will help you understand these changes — and what you should do about them.
Every millisecond counts when it comes to loading Web pages and their responsiveness. It has become critical to optimise the performance of Web applications/pages to retain existing visitors and bring in new customers. If you are eager to explore the world of Web optimisation, then this article is the right place to start.
The World Wide Web has evolved into the primary channel to access both information and services in the digital era. Though network speed has increased many times over, it is still very important to follow best practices when designing and developing Web pages to provide optimal user experiences. Visitors of Web pages/applications expect the page to load as quickly as possible, irrespective of the speed of their network or the capability of their device.
Along with quick loading, another important parameter is to make Web applications more responsive. If a page doesn’t meet these two criteria, then users generally move out of it and look for better alternatives. So, both from the technical and economical perspectives, it becomes very important to optimise the responsiveness of Web pages.
Optimisation cannot be thought of just as an add-on after completing the design of the page. If certain optimisation practices are followed during each stage of Web page development, these will certainly result in a better performance. This article explores some of these best practices to optimise the performance of the Web page/application.
Web page optimisation is an active research domain in which there are contributions from so many research groups. An easy-to-use Web resource to start with the optimisation of Web pages is provided by Yahoo (https://developer.yahoo.com/performance/rules.html). There are other informative resources, too, such as BrowserDiet (https://browserdiet.com/en/#html). Various other factors that contribute to Web page optimisation are shown in Figure
Content optimisation
When responding to end user requests, the most time is taken up by the downloading of components such as images, scripts, Flash and style sheets.
The greater the number of HTTP requests, the more the time required for the page to load and its responsiveness lessens. A critical mechanism to reduce the number of HTTP requests is to reduce the number of components in the Web page. This may be achieved by combining several components. For example, all scripts can be combined, many CSS style sheets can be merged together, etc.
Minimising the DNS lookup is another important factor in optimisation. The primary role of Domain Name Systems is the mapping of human readable domain names to IP addresses. DNS lookups generally take somewhere between 20 and 120 milliseconds. Minimising the number of unique host names will reduce the number of DNS resolution attempts.
Reducing the redirects can increase speed. These redirects are performed with 301 and 302 status codes.
With respect to Web 2.0 / 3.0 / 4.0 applications, caching of AJAX (Asynchronous JavaScript And XML) requests is an important step.
The number of DOM (Document Object Model) elements should be kept under control.
Server optimisation
Using a Content Delivery Network (CDN) can help in optimising the Web page’s performance. Geographical proximity to the user has a positive impact on the time required to fetch content.
A cache-control header can help. If the content is static, then the expiry should be set as Never Expire. For dynamic content, the time up to when the component is valid should be set. This will minimise HTTP requests.
Compressing the components is another great step in optimisation. This can be achieved with ‘Gzip’. Experts estimate that the compression minimises the time required for responses by 70 per cent.
With respect to AJAX applications, the GET method is preferable. So, along with XMLHttpRequest, as far as possible use the GET method.
Cookies
Cookies are one of the most used mechanisms by Web developers to store tiny pieces of information. With respect to cookies, the following factors should be considered:
Size of the cookies should be kept minimal.
Cookies should be set at the appropriate level in the domain hierarchy. This is done to reduce the impact on sub-domains.
Don’t forget to set a proper expiry date for the cookie.
Style sheets
Professionally designed style sheets make Web pages look elegant. The following factors must be considered in handling style sheets:
It is better to keep the style sheets in the HEAD section of the Web pages. This is done to permit the pages to render incrementally.
Care should be taken to use expressions in CSS. Mathematical expressions in CSS are evaluated a lot more times than the developer might actually expect. Avoid them as far as possible.
If you have to include multiple CSS files, merge them all into one file. This reduces the number of HTTP requests.
Opt to use <link> over the @import when using CSS in a page.
JavaScript
JavaScript has become the de-facto client-side scripting language. So the way in which JavaScript components are built does have a significant impact on the performance of Web pages.
If possible, move the script to the bottom of the page. This cannot be done always (for example, if your page’s critical contents are rendered through the document.write() function).
Using external JavaScript and style sheet files will enable better caching. So, it would be better in many scenarios to put CSS and JavaScript through the external mode.
Minifying and Obfuscation are two effective mechanisms to improve the performance by tweaking the code. One survey indicates that obfuscation can achieve a 25 per cent reduction in size.
Crowding of events needs to be avoided. Delegating events properly improves the performance of the page.
The usage of async (asynchronous) must be encouraged, as shown below:
<script async src=”example.js”></script>
If you don’t use the aysnc keyword then the page has to wait till the example.js is fully downloaded. The aysnc keyword makes page parsing happen even before the downloading of the script is completed. Once the script is downloaded, it is activated. However, when using multiple async, the order of execution becomes a concern.
Optimising images
Images are an integral part of most Web pages. Hence, the way images are handled defines the performance of the application. The following factors should be considered:
Scaling down of images using HTML tags should be avoided. There is no point in using a bigger image and resizing it using the width and height attributes of the <img> tag.
When using Data URI, the contents can be given in inline mode. This can be done for smaller sized images.
Images generally contain data that are not required in Web usage. For example, the EXIF metadata can be stripped before uploading to the server.
There are many tools to help you optimise images, such as TinyPNG, Compressor.io, etc. There are command line based tools also, such as jpegtran, imgopt, etc.
Performance analysis tools
There are many tools available to analyse the performance of Web pages. Some of these tools are illustrated in above Figure
There are component-specific tools, too. For example, for benchmarking JavaScript, the following tools may be used:
JSPerf
Benchmark.js
JSlitmus
Matcha
Memory-stats.js
For PHP, tools such as PHPench and php-bench could be harnessed.
Minifiers
As stated earlier, minifying is one of the optimisation techniques, for which there are many tools. For HTML, the following Minifiers could be tried out:
HTMLCompressor
HTMLMinifier
HTML_press
Minimize
Some of the tools used for Minifying JavaScript and CSS are listed below:
Uglifyjs2
CSSmin.js
Clean-css
JShrink
JSCompress
YUI Compressor
Benchmarking Web servers
Benchmarking of Web servers is an important mechanism in Web page/application optimisation. Table 1 provides a sample list of tools available for benchmarking Web servers.
The Web optimisation domain is really huge. This article has just provided a few start-up pointers, using which interested developers can proceed further in understanding the advanced technicalities of the topic.
Today, apart from relational tables, data is also available in other forms such as images, texts, blogs, lists, etc. Redis can be used as a database, cache and message broker. It is exceptionally fast, and can support five data types and two special types of data.
Redis is an open source, in-memory and key/value NoSQL database. Known to be an exceptionally fast in-memory database, Redis is used as a database, cache and message broker, and is written in C. It supports five data types— strings, hashes, lists, sets, sorted sets and two special types of data—Bitmap and HyperLogLog.
Since Redis runs in memory, it is very fast but is disk persistent. So in case a crash happens, data is not lost. Redis can perform about 110,000 SETs and about 81,000 GETs per second. This popular database is used by many companies such as Pinterest, Instagram, StackOverflow, Docker, etc.
There are several problems that Redis addresses, which are listed below.
Session cache: Redis can be used to cache user sessions. Due to its in-memory data structure as well as data persistent nature, Redis is a prefect choice for this use case.
Middle layer: If your program delivers data at a very fast rate but the process of storing data in a database such as MySQL is very slow, then you can use Redis as the middle layer. Your program will just put the data into Redis, and another program will pull the data and store it in the database.
Shows the latest items listed in your home page: Due to fast retrieval, you can show the important data to users from Redis. The rest of the data can be fetched from the database later.
It acts as a broker for Celery processes.
Installation of Redis
You can download a stable version of Redis from https://redis.io/download. We are going to install Redis on Centos 6.7 —you can use Ubuntu or Debian. Let us extract the tar package of Redis, for which you can use the following command:
$ tar -xvzf redis-3.2.8.tar.gz
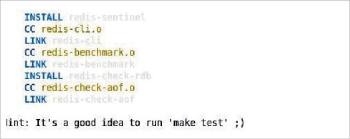
After extraction, a directory redis-3.2.8 will be formed. Just use one command, make, to install the Redis. Sometimes, an error occurs while installing Redis:
In file included from adlist.c:34:
zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directory
zmalloc.h:55:2: error: #error “Newer version of jemalloc required”
make[1]: *** [adlist.o] Error 1
make[1]: Leaving directory `/root/redis/redis-3.2.8/src’
If the above error occurs, then use the command given below:
make MALLOC=libc && make install
Figure 1 shows that Redis has been successfully installed.
Starting Redis
Just take a look at the directory redis-3.2.8 (Figure 2). You will find the redis.conf file in it. In order to start Redis, we need to configure this file.
Let us consider a main configuration of the file:
bind 127.0.0.1
If you are using a static IP, then you can give the static IP address; otherwise, 127.0.0.1 is okay.
The default port of Redis is 6739.
pidfile /var/run/redis_6379.pid
The above line gives the location of pidfile, and if you are not running as root then you can give your custom path:
logfile “”
By default, it is blank but you can give the log file path; try to give the absolute path.
The above line gives the name of the dump file that stores the database.
dir ./
The above option specifies the location of the dump.rdb file.
daemonize yes
By default, the above option is set as ‘no’. When you run the Redis server, it shows progress on the terminal but, in a development environment, the Redis server must be run in the background. So, set it as ‘yes’.
Let us now start Redis. In Figure 2, there is a directory src, which contains Redis binaries.
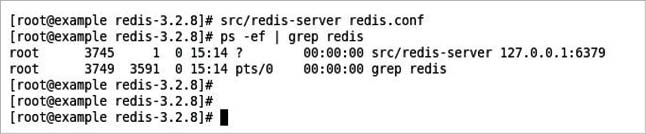
The command to run the Redis server is as follows:
# src/redis-server redis.conf
See Figure 3, which shows that Redis is running.
Redis supports master-slave replication, which allows slave Redis servers to be exact copies of master servers. The master/slave replication is one way of achieving scalability. The slave is read-only and the master is read and write. When a data update happens on the master, it eventually affects the slave.
Creating a Redis slave
In order to start a slave, you will need a conf file. So make a copy of redis.conf as redis-slave.conf:
# cp redis.conf redis-slave.conf
Next, open redis-slave.conf. And change the settings as shown below:
pidfile /var/run/redis_6380.pid
logfile "/var/run/redis_6379-s.log"
port 6380
slaveof 127.0.0.1 6379
The above settings set the port number of the slave and tell the slave about its master.
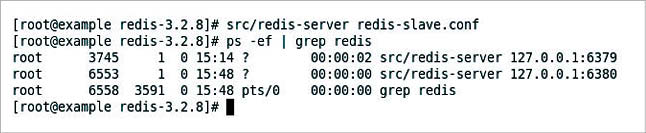
Start the slave and follow the process, as shown in Figure 4.
The Redis master and slave are both running now.
Redis commands
To run commands on the Redis remote server, we will use the redis-cli command syntax:
Let us take a look at some useful commands for a fresh start. Set, get and del: These three commands set the key values. See the following example.
127.0.0.1:6379> set "one" 1
OK
127.0.0.1:6379> get one
"1"
127.0.0.1:6379> del one
(integer) 1
127.0.0.1:6379> get one
(nil)
127.0.0.1:6379>
In the above example, ‘one’ is the key and 1 is the value. Lpush, lrange, rpush:These are three more useful commands.
The lpush command pushes the values from the left side.
You can see that rpop pops the value from the right and lpop pops the value from the left.
There are many other useful commands that you will find in the documentation on Redis.
Using Redis with Python
In order to use Redis with Python, you will need redis-py. You can download redis-py from https://pypi.python.org/pypi/redis. I am using redis-2.10.5.tar.gz.
Extract the tar package, as follows:
# tar -xvzf redis-2.10.5.tar.gz
Use the following command to install it:
python setup.py install
Let us write a Python script to perform Redis operations as we did earlier with redis-cli.
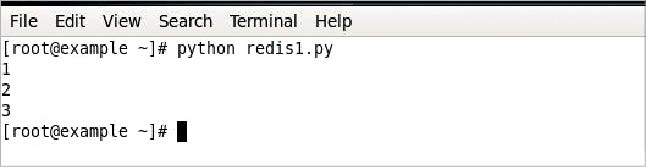
I am going to write a simple Python script named redis1.py:
See the output in Figure 5.
Let us create another program redis3.py, which pops the value from the left as well as from the right.
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
r.rpush("list1","one")
r.rpush("list1","two", "three", "four")
print r.lrange("list1",0,-1)
print "pop from right ", r.rpop('list1')
print "pop from left ",r.lpop('list1')
print r.lrange("list1",0,-1)
The above program is very easy to understand. The results we have achieved in the above program are the same as what we achieved in redis-cli mode. See the output in Figure 6.
While there are a lot of advantages of using Redis, there are some disadvantages too. You should have more memory than your data requires, because Redis forks on each snapshot dump, which can consume extra memory. Also, you can’t roll back a transaction.
In programming, you must always take care of the number of connections. Sometimes people are lazy while programming, leading to the ‘max client reached problem’.
Alternatives to Redis
Well, this totally depends upon the situation. If you just need fast retrieval, you can use Memcache, but this does not store data on the disk. NoSQL databases like MongoDB and Couchbase might be alternatives for some use cases.
This is a discussion on the role of Docker in software development and how it scores over virtual machines. As it becomes increasingly popular, let’s look at what the future holds for Docker.
We all know that Docker is simple to get up and running on our local machines. But seamlessly transitioning our honed application stacks from development to production is problematic.
Docker Cloud makes it easy to provision nodes from existing cloud providers. If you already have an account with an Infrastructure-as-a-Service (IaaS) provider, you can provision new nodes directly from within Docker Cloud, which can play a crucial role in digital transformation.
For many hosting providers, the easiest way to deploy and manage containers is via Docker Machine drivers. Today we have native support for nine major cloud providers:
Amazon Web Services
Microsoft Azure
Digital Ocean
Exoscale
Google Compute Engine
OpenStack
Rackspace
IBM Softlayer
Packet.net
AWS is the biggest cloud-hosting service on the planet and offers support for Docker across most of its standard EC2 machines. Google’s container hosting and management service is underpinned by Kubernetes, its own open source project that powers many large container-based infrastructures. More are likely to follow soon, and you may be able to use the generic driver for other hosts.
Docker Cloud provides a hosted registry service with build and testing facilities for Dockerised application images, tools to help you set up and manage host infrastructure, and application life cycle features to automate deploying (and redeploying) services created from images. It also allows you to publish Dockerised images on the Internet either publicly or privately. Docker Cloud can also store pre-built images, or link to your source code so it can build the code into Docker images, and optionally test the resulting images before pushing them to a repository.
Virtual machines (VM) vs Docker
Some of the companies investing in Docker and containers are Google, Microsoft and IBM. But just because containers are extremely popular, that doesn’t mean virtual machines are out of date. Which of the two is selected depends entirely on the specific needs of the end user.
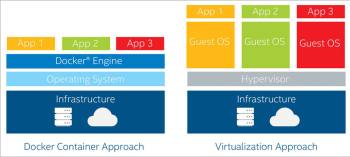
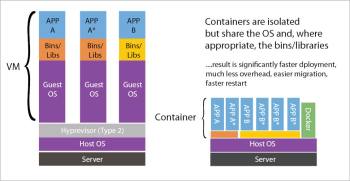
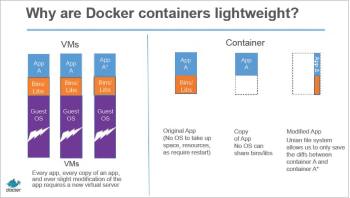
Virtual machines (VMs) run on top of a hypervisor with a fully virtualised and totally isolated OS. They take up a lot of system resources and are also very slow to move around. Each VM runs not just a full copy of an operating system, but a virtual copy of all the hardware that the operating system needs to run. This quickly adds up to a lot of RAM and CPU cycles. And yes, containers can enable your company to pack a lot more applications into a single physical server than a VM can. Container technologies such as Docker beat VMs at this point in the cloud or data centre game.
Virtual machines are based on the concept of virtualisation, which is the emulation of computer hardware. It emulates hardware like the CPU, RAM and I/O devices. The software emulating this is called a hypervisor. Every VM interacts with the hypervisor through the operating system installed on the VM, which could be a typical desktop or laptop OS. There are many products that provide virtualised environments like Oracle VirtualBox, VMware Player, Parallel Desktop, Hyper-V, Citrix XenClient, etc.
Docker is based on the concept of containerisation. A container runs in an isolated partition inside the shared Linux kernel running on top of the hardware. There is no concept of emulation or a hypervisor in containerisation. Linux namespaces and cgroups enable Docker to run applications inside the container. In contrast to VMs, all that a container requires is enough of an operating system, supporting programs and libraries, and system resources to run a specific program. This means that, practically, you can put two to three times as many applications on a single server with containers than you can with a VM. In addition, with containers you can create a portable, consistent operating environment for development, testing and deployment. That’s a winning triple whammy.
Why Docker instead of VMs?
Faster delivery of applications.
Portable and scales more easily.
Get higher density and run more of a workload.
Faster deployment leads to easier management.
Docker features
VE (Virtual Environments) based on LXC.
Portable deployment across machines.
Versioning: Docker includes Git-like capabilities for tracking versions of a container.
Component reuse: It allows building or stacking of already created packages. You can create ‘base images’ and then run more machines based on the image.
Shared libraries: There is a public repository with several images.
Docker containers are very lightweight.
Who uses Docker and containers?
Many industries and companies have today shifted their infrastructure to containers or use containers in some other way.
The leading industries using Docker are energy, entertainment, financial, food services, life sciences, e-payments, retail, social networking, telecommunications, travel, healthcare, media, e-commerce, transportation, education and technology.
Some of the companies and organisations using Docker include The New York Times, PayPal, Business Insider, Cornell University, Indiana University, Splunk, The Washington Post, Swisscomm, GE, Groupon, Yandex, Uber, Shopify, Spotify, New Relic, Yelp, Quora, eBay, BBC News, and many more. There are many other companies planning to migrate their existing infrastructure to containers.
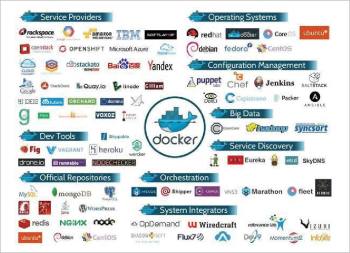
Integration of different tools
With the integration of various major tools available in the market now, Docker allows developers and IT operations teams to collaborate with each other to build more software faster while remaining secure. It is associated with service provider tools, dev tools, official repositories, orchestration tools, systems integration tools, service discovery tools, Big Data, security tools, monitoring and logging tools, configuration management tools such as those used for continuous integration, etc.
Continuous integration (CI) is another big area for Docker. Traditionally, CI services have used VMs to create the isolation you need to fully test a software app. Docker’s containers let you do this without using a lot of resources, which means your CI and your build pipeline can move more quickly.
Continuous integration and continuous deployment (CD) have become one of the most common use cases of Docker early adopters. CI/CD merges development with testing, allowing developers to build code collaboratively, submit it to the master branch and check for issues. This allows developers to not only build their code, but also test it in any environment type and as often as possible to catch bugs early in the applications development life cycle. Since Docker can integrate with tools like Jenkins and GitHub, developers can submit code to GitHub, test it and automatically trigger a build using Jenkins. Then, once the image is complete, it can be added to Docker registries. This streamlines the process and saves time on build and set-up processes, all while allowing developers to run tests in parallel and automate them so that they can continue to work on other projects while tests are being run. Since Docker works on the cloud or virtual environment and supports both Linux and Windows, enterprises no longer have to deal with inconsistencies between different environments – which is perhaps one of the most widely known benefits of the Docker CaaS (Containers as a Service) platform.
Drone.io is a Docker-specific CI service, but all the big CI players have Docker integration anyway, including Jenkins, Puppet, Chef, Saltstack, Packer, Ansible, etc; so it will be easy to find and incorporate Docker into your process.
Adoption of Docker
Docker is probably the most talked about infrastructure technology in the past few years. A study by Datadog, covering around 10,000 companies and 185 million containers in real-world use, has resulted in the largest and most accurate data review of Docker adoption. The following highlights of this study should answer all your questions.
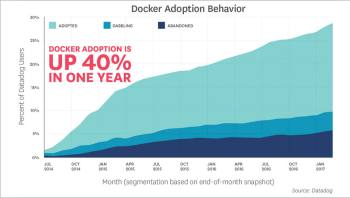
i) Docker adoption has increased 40 per cent in one year
At the beginning of March 2016, 13.6 per cent of Datadog’s customers had adopted Docker. One year later, that number has grown to 18.8 per cent. That’s almost 40 per cent market-share growth in 12 months. Figure 7 shows the growth of Docker adoption and behaviour. Based on this, we can say that companies are adopting Docker very fast and it’s playing a major role in global digital transformation.
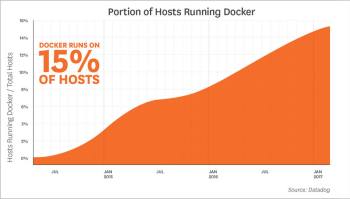
ii) Docker now runs on 15 per cent of the hosts
This is an impressive fact. Two years ago, Docker had about 3 per cent market share, and now it’s running on 15 per cent of the hosts Datadog monitors. The graph in Figure 8 illustrates that the Docker growth rate was somewhat variable early on, but began to stabilise around the fall of 2015. Since then, Docker usage has climbed steadily and nearly linearly, and it now runs on roughly one in every six hosts that Datadog monitors.
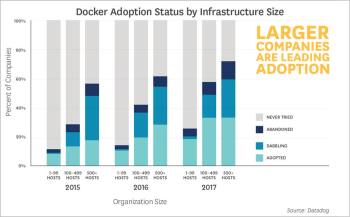
iii) Larger companies are leading adoption
Larger companies tend to be slower to move. But in the case of Docker, larger companies are leading the way since the first edition of Datadog’s report in 2015. The more hosts a company uses, the more likely it is to have tried Docker. Nearly 60 per cent of organisations running 500 or more hosts are classified as Docker dabblers or adopters.
While previous editions of this report showed organisations with many hosts clearly driving Docker adoption, the latest data shows that organisations with mid-sized host counts (100–499 hosts) have made significant gains. Adoption rates for companies with medium and large host counts are now nearly identical. Docker first gained a foothold in the enterprise world by solving the unique needs of large organisations, but is now being used as a general-purpose platform in companies of all sizes.
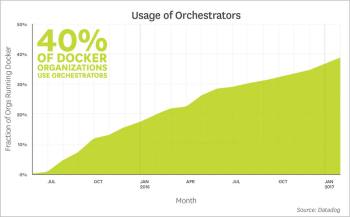
iv) Orchestrators are taking off
As Docker increasingly becomes an integral part of production environments, organisations are seeking out tools to help them effectively manage and orchestrate their containers. As of March 2017, roughly 40 per cent of Datadog customers running Docker were also running Kubernetes, Mesos, Amazon ECS, Google Container Engine, or another orchestrator. Other organisations may be using Docker’s built-in orchestration capabilities, but that functionality did not generate uniquely identifiable metrics that would allow us to reliably measure its use at the time of this report.
Among organisations running Docker and using AWS, Amazon ECS is a popular choice for orchestration, as would be expected — more than 35 per cent of these companies use ECS. But there has also been significant usage of other orchestrators (especially Kubernetes) at companies running AWS infrastructure.
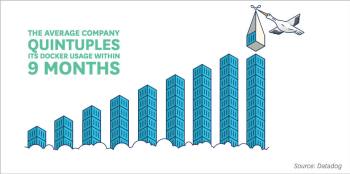
v) Adopters quintuple their container count within nine months
The average number of running containers Docker adopters have in production grows five times between their first and tenth month of usage. This internal-usage growth rate is quite linear, and shows no signs of tapering off after the tenth month. Another indication of the robustness of this trend is that it has remained steady since Datadog’s previous report last year.
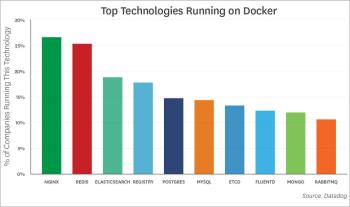
vi) Top technologies/companies running on Docker technology
The most common technologies running in Docker are listed below.
NGINX: Docker is being used to contain a lot of HTTP servers, it seems. NGINX has been a perennial contender on this list since Datadog began tracking image use in 2015.
Redis: This popular key-value data store is often used as an in-memory database, message queue, or cache.
ElasticSearch: Full-text search continues to increase in popularity, cracking the top three for the first time.
Registry: Eighteen per cent of companies running Docker are using Registry, an application for storing and distributing other Docker images. Registry has been near the top of the list in each edition of this report.
Postgres: The increasingly popular open source relational database edges out MySQL for the first time in this ranking.
MySQL: The most widely used open source database in the world continues to find use in Docker infrastructure. Adding the MySQL and Postgres numbers, it appears that using Docker to run relational databases is surprisingly common.
etcd: The distributed key-value store is used to provide consistent configuration across a Docker cluster.
Fluentd: This open source ‘unified logging layer’ is designed to decouple data sources from backend data stores. This is the first time Fluentd has appeared on the list, displacing Logsout from the top 10.
MongoDB: This is a widely-used NoSQL datastore.
RabbitMQ: This open source message broker finds plenty of use in Docker environments.
vii) Docker hosts often run seven containers at a time
The median company that adopts Docker runs seven containers simultaneously on each host, up from five containers nine months ago. This finding seems to indicate that Docker is in fact commonly used as a lightweight way to share compute resources; it is not solely valued for providing a knowable, versioned runtime environment. Bolstering this observation, 25 per cent of companies run an average of 14+ containers simultaneously.
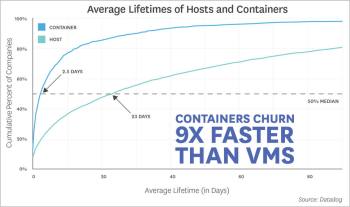
viii) Containers’ churn rate is 9x faster than VMs
At companies that adopt Docker, containers have an average lifespan of 2.5 days, while across all companies, traditional and cloud-based VMs have an average lifespan of 23 days. Container orchestration appears to have a strong effect on container lifetimes, as the automated starting and stopping of containers leads to a higher churn rate. In organisations running Docker with an orchestrator, the typical lifetime of a container is less than one day. At organisations that run Docker without orchestration, the average container exists for 5.5 days.
Containers’ short lifetimes and increased density have significant implications for infrastructure monitoring. They represent an order-of-magnitude increase in the number of things that need to be individually monitored. Monitoring solutions that are host-centric, rather than role-centric, quickly become unusable. We thus expect Docker to continue to drive the sea change in monitoring practices that the cloud began several years ago.
You might be thinking of developing a mobile application, but confused how to go about it or from where to start due to the various technologies available to develop apps? Also, which is the best for your business – a native app or a hybrid app? Let’s find out.
Your choice of a native or a hybrid app will depend on several contrasting factors including your budget, targeted audience and your deadline. The very moment you decide to invest in a mobile app, you immediately come across loads of terminology.
You need to know the difference between iOS and Android and the nature of native, hybrid and web apps. And very importantly, you also need to find out which app is the most suitable for you. So, in this article, we will go through all the differences between the two types of apps, understand which one to use and will make you aware of some of the benefits of each.
What is native mobile app?
A native mobile application is a smartphone program that has been created for use with a particular platform or device like for iOS, Android, Blackberry and so on. Native apps are encoded in a particular programming language such as Objective C for iOS and Java for Android operating systems. Native mobile apps are fast and more efficient in terms of performance. They also have access to the built-in features of the handset, like its camera, address book, GPS, accelerometer, compass and the list of contacts. Moreover, these apps are quite well supported by the platform owners along with specific libraries and support.
One unique factor about native apps is that users can use some apps without an internet connection. But note, this kind of app is expensive to build because it is generally designed to run on a particular operating system or a specific device, the one based on either iOS or Android.
A large number of video games for mobile devices are native mobile apps, while examples of native apps include a majority of the well-known apps out there like the Facebook app, Twitter app and Waze are native.
What is a hybrid mobile app?
Hybrid apps are created for use on multiple platforms (Android, iPhone and Windows Phone). They are those web applications (or web pages) that you can run in a native browser. Examples of such apps include UIWebView in iOS and WebView in Android (not Safari or Chrome).
These apps are developed using HTML5, CSS and Javascript and then embedded in a native application using platforms like Cordova. Their development is faster and simpler. Also, such apps support multiple operating systems at minimal cost than developing multiple native apps and makes the apps more flexible to maintain. You can change platforms anytime you need.
Cordova is an open source tool that allows you to build your hybrid applications which can run on more than one platform just by one adding the right line of code. Also, Hybrid apps have access to phone hardware (native functions) such as the camera, microphone, location and Bluetooth. Cordova has a large repository of plugins that can ease your hybrid app development.
The major challenge with hybrid apps is that they still depend on the native browser, which simply means they are not as fast as native apps.
Key differences between native and hybrids mobile apps
Features
Native Apps
Hybrid Apps
Device access
Full
Full
Performance
High/Fast
Medium/Good
Development Language
Objective C for iOS or Java for Android operating systems
HTMLS, CSS and JavaScript
Development Cost
Expensive
Reasonable
Development Time
High
Medium
Offline mode
Supported
Not Supported
Maintenance
High
Medium
Speed
Very Fast
Good
Cross Platform Support
No
Yes
User Interface
Good
Good
UI/UX
HIGH
Moderate
Advance Graphics
Moderate
HIGH
Security
High
Low
Code Portability
Low
High
Complexity
More complex to code
Less complex to code
User experience
Better user experience
Less user experience than native apps
Graphics
Better graphics
Lesser graphics than native apps
Portability
Harder to port to other systems
Easier to port to other systems
Integration
The camera, address book, geolocation, and other features native to the device can be seamlessly integrated into native apps.
Some device features may be harder to integrate into hybrid apps.
Internet Connection
Not Required Always
Required
Gesture Support
Yes
Yes
Advantages and disadvantages of native and hybrid apps
Both native and hybrid apps have ways to meet different needs and purpose of users and developers, but none of them can be said to be the perfect solution. These apps have their pros and cons — both for an app developer and as an end user. So, you have to decide which of suits you better or which app is ideal for your business needs.
Pros of native apps:
Full integration of device
Native apps are those apps that come with many functionalities offered by the mobile devices. For instance, camera, GPS, calendar and microphone. These apps help the users to build the experience which is fully enjoyable and provides a great exposure.
Work without Internet connection
The most important feature of native apps is that these apps also work without an Internet connection. It, however, the functionality depends on the nature of the apps.
Excellent performance
If you are looking for a high-speed app or game, then a native app should be your pick. Native apps get designed or developed for some specific operating systems, and they provide great performance.
Look and feel of native applications
The trendy look and feel of native applications are eye-catching and inspiring — allowing users to connect easily and quickly to the icons and button.
Better UX standards
All the native apps follow the specific UX/UI standards for creating Android or iOS applications, which let the users easily understand the interface and navigation of the apps.
More secure and safe
All the native apps on Android or iOS are only accessible through the app stores. Before all the apps get approved to be featured in the stores, they are fully tested and reviewed by the app store approval team. This provides a certificate of reliability and assurance.
Cons of native apps:
Higher development and maintenance expenses
Native apps are quite complex since they have a different codebase for each platform and to maintain them, it requires a lot of time and effort since separate teams have to work and support each version natively.
No guarantee that apps will get accepted
Once the applications are created, then it is required to get approval from the play store/app store. And it is a quite long and tedious process because all the applications have to get approved from the store to get featured. Also, there might be a possibility that the application might get rejected and will be not added to the App store databases.
Pros of hybrid apps:
Unified development
The principle advantage of hybrid apps arises from the fact that you are saving the stress of building multiple apps; you are building one app and tweaking it slightly. This makes the single app to be operable on both platforms and offers unified development. It allows the companies to save the amount of money in developing more than a single app for leading platforms. Developers can develop a single hybrid framework, and the common codebase can be used flawlessly for different platforms.
Only one codebase to deal with
Hybrid apps are easier to maintain as you have to manage only one codebase. While developing hybrid apps, you require fewer developers as compared to the native apps, which ensures smooth and efficient productivity.
Fastest development speed
Hybrid apps can be developed quickly, without much efforts in a short period. These apps also require less maintenance as compared to native apps and are flexible; they are easier to transform into another platform. By building one app on a platform, you can easily launch it on another.
Efficient scaling
Hybrid apps are known as cross-platform applications which are easy to scale on different platforms and different operating devices. It allows the development team to reuse the code without making many changes in the application.
Offline support
Hybrid apps support offline work, but while working the offline data cannot be updated.
less cost
One of the unique qualities of hybrid apps is that they use web technologies for app content. This makes the building of hybrid apps much easier. Web technology knowledge outweighs native app’s coding and provides more leverage for resources.
Interactive components
Visuals and interactive programs like games and 3D animation are present in hybrid apps, but these programs still work much better on full native apps. Businesses are not likely to have a more graphical and platform specific needs like games or animated apps, which is the main reason why hybrid apps are ideal for business professional services apps. Fortunately, more innovations are being introduced into hybrid apps on a daily basis, and they have been catching up with their native cousins.
Cons of hybrid apps:
Slow performance
Hybrid apps are a bit slower because they are based on the web technologies along with utilising mobile platforms such as Kendo, Onsen, Ionic and Cordova. All these platforms’ take considerable more time according to the application, which can result in loss of performance. It is also one of the biggest flaws because if the user will not get an impressive experience, then the likelihood of the application becoming popular goes down.
Poor UX
One of the serious disadvantages of a hybrid app is that they never offer a user the full native experience. In the app domain, the user very rarely gives the apps a fifth or sixth chance. So, the UX has to be up there with the best and flawless. The hybrid apps still have some way to go before they catch up with their native cousins on the UX front.
Which one should you choose?
To make the right choice, it is important to understand the differences between native and hybrid apps. Each has its own strengths and weaknesses, and your ultimate decision depends almost entirely on your business needs.
Usually, Hybrid apps attract more because of their easy availability approach, cost savings and their compatibility with more technologies and platforms. All these things are very appealing, but if we look at a longer term, then the hybrid apps can become a pain sometimes since they would need more time to fix the UX and performance issues which the users might report.
Whereas, if we look at the native apps, then these apps fully satisfy the users in terms of performance and with their seamless use of the platform’s built-in functions. These apps offer the best in class security for a mobile application, i.e., highly user interface design, best performance and access to the native APIs. However, you need a bigger investment in the beginning, but if we look at a long run, the investment helps you save your time and money in the future by offering a better user experience and following the platform and industry standards.
In the end, each organisation has its own approach to designing an application. So it fully depends on you on which path to choose and follow.
Databases are key components of many an app and choosing the right option is an elaborate process. This article examines the role that databases play in apps, giving readers tips on selecting the right option. It also discusses the pros and cons of a few select databases.
Every other day we discover a new online application that tries to make our lives more convenient. And as soon as we get to know about it, we register ourselves for that application without giving it a second thought. After the one-time registration, whenever we want to use that app again, we just need to log in with our user name and password —the app or system automatically remembers all our data that was provided during the registration process. Ever wondered how a system is able to identify us and recollect all our data on the basis of just a user name and password? It’s all because of the database in which all our information or data gets stored when we register for any application.
Similarly, when we browse through millions of product items available on various online shopping applications like Amazon, or post our selfies on Facebook to let all our friends see them, it’s the database that is making all this possible.
According to Wikipedia, a database is an organised collection of data. Now, why does data need to be in an organised form? Let’s flash back to a few years ago, when we didn’t have any database and government offices like electricity boards stored large heaps of files containing the data of all users. Imagine how cumbersome it must have been to enter details pertaining to a customer’s consumption of electricity, payments made or pending, etc, if the names were not listed alphabetically. It would have been time consuming as well. It’s the same with databases. If the data is not present in an organised form, then the processing time in fetching any data is quite long. The data stored in a database can be in any organised form—schemas, reports, tables, views or any other objects. These are basically organised in such way as to help easy retrieval of information. The data stored in files can get lost when the papers of these files get older and, hence, get destroyed. But in a database, we can store data for millions of years without any such fear. Data will get lost only when the system crashes, which is why we keep a backup.
Now, let’s have a look at why any application needs a database.
It will be difficult for any online app to store huge amounts of data for millions of its customers without a database.
Apart from storing data, a database makes it quite easy to update any specific data (out of a large volume of data already residing in the database) with newer data.
The data stored in a database of an app will be much more secure than if it’s stored in any other form.
A database helps us easily identify any duplicate set of data present in it. It will be quite difficult to do this in any other data storage method.
There is the possibility of users entering incomplete sets of data, which can add to the problems of any application. All such cases can be easily identified by any database.
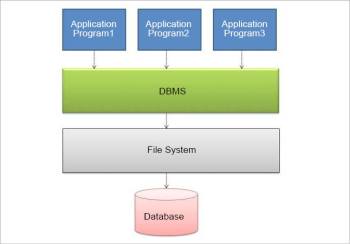
A user cannot directly interact with any database—there needs to be an interface or intermediate system, which helps the user to interact with it. Such an interface is referred to as a database management system (DBMS). It is basically a computer software application that interacts with the user or other applications, and even with the database itself, in order to capture and analyse the data. Any DBMS such as MySQL is designed in such a way that it allows the definition, querying, creation, updation and administration of the whole database. It is where we request the database to give us the required data in the query language.
Different types of databases
Relational database: This is one of the most common of all the different types of available databases. In such types of databases, the data is stored in the form of data tables. Each table has a unique key field, which is used to connect it to other tables. Therefore, all the tables are related to each other with the help of several key fields. These databases are used extensively in different industries and will be the type we are most likely to come across when working in IT.
Operational database: An operational database is quite important for organisations. It includes the personal database, customer database and inventory database, all of which cover details of how much of any product the company has, as well as the information on the customers who buy the products. The data stored in different operational databases can be changed and manipulated based on what the company requires.
Data warehouses:Many organisations are required to keep all relevant data for several years. This data is also important for analysing and comparing the present year data with that of the previous year, to determine key trends. All such data, collected over years, is stored in a large data warehouse. As the stored data has gone through different kinds of editing, screening and integration, it does not require any more editing or alteration.
Distributed databases:Many organisations have several office locations—regional offices, manufacturing plants, branch offices and a head office. Each of these workgroups may have their own set of databases, which together will form the main database of the company. This is known as a distributed database.
End user databases:There is a variety of data available at the workstation of all the end users of an organisation. Each workstation acts like a small database in itself, which includes data in presentations, spreadsheets, Word files, downloaded files and Notepad files.
Choosing the right database for your application
Choosing the right database for an application is actually a long-term decision, since making any changes at a later point can be difficult and even quite expensive. So, we cannot even afford to go wrong the first time. Let’s see what benefits we will get if we choose the right database the first time itself.
Only if we choose the right database will the relevant and the required information get stored in the database, putting data in a consistent form.
It’s always preferable that the database design is normalised. It helps to reduce data redundancy and even prevents duplication of data. This ultimately leads to reducing the size of the database.
If we choose the correct database, then the queries fired in order to fetch data will be simple and will get executed faster.
The overall performance of the application will be quite good.
Choosing the right database for an application also helps in easy maintenance.
Factors to be considered while choosing the right database for your application
Well, there is a difference between choosing any database for an application and choosing the right database for it. Let’s have a look at some of the important factors to be considered while choosing a database for an application.
Structure of data: The structure of the data basically decides how we need to store and retrieve it. As our applications deal with data present in a variety of formats, selecting the right database should include picking the right data structures for storing and retrieving the data. If we do not select the right data structures for persisting our data, our application will take more time to retrieve data from the database, and will also require more development efforts to work around any data issues.
Size of data to be stored: This factor takes into consideration the quantity of data we need to store and retrieve as critical application data. The amount of data we can store and retrieve may vary depending on a combination of the data structure selected, the ability of the database to differentiate data across multiple file systems and servers, and even vendor-specific optimisations. So we need to choose our database keeping in mind the overall volume of data generated by the application at any specific time and also the size of data to be retrieved from the database.
Speed and scalability: This decides the speed we require for reading the data from the database and writing the data to the database. It addresses the time taken to service all incoming reads and writes to our application. Some databases are actually designed to optimise read-heavy applications, while others are designed in a way to support write-heavy solutions. Selecting a database that can handle our application’s input/output needs can actually go a long way to making a scalable architecture.
Accessibility of data: The number of people or users concurrently accessing the database and the level of computation involved in accessing any specific data are also important factors to consider while choosing the right database. The processing speed of the application gets affected if the database chosen is not good enough to handle large loads.
Data modelling:This helps map our application’s features into the data structure and we will need to implement the same. Starting with a conceptual model, we can identify the entities, their associated attributes, and the entity relationships that we will need. As we go through the process, the type of data structures we will need in order to implement the application will become more apparent. We can then use these structural considerations to select the right category of database that will serve our application the best.
Scope for multiple databases:During the modelling process, we may realise that we need to store our data in a specific data structure, where certain queries cannot be optimised fully. This may be because of various reasons such as some complex search requirements, the need for robust reporting capabilities, or the requirement for a data pipeline to accept and analyse the incoming data. In all such situations, more than one type of database may be required for our application. When choosing more than one database, it’s quite important to select one database that will own any specific set of data. This database acts as the canonical database for those entities. Any additional databases that work with this same set of data may have a copy, but will not be considered as the owner of this data.
Safety and security of data: We should also check the level of security that any database provides to the data stored in it. In scenarios where the data to be stored is highly confidential, we need to have a highly secured database. The safety measures implemented by the database in case of any system crash or failure is quite a significant factor to keep in mind while choosing a database.
A few open source database solutions available in the market
MySQL
MySQL has been around since 1995 and is now owned by Oracle. Apart from its open source version, there are also different paid editions available that offer some additional features, like automatic scaling and cluster geo-replication. We know that MySQL is an industry standard now, as it’s compatible with just about every operating system and is written in both C and C++. This database solution is a great option for different international users, as the server can provide different error messages to clients in multiple languages, encompassing support for several different character sets.
Pros
It can be used even when there is no network available.
It has a flexible privilege and password system.
It uses host-based verification.
It has security encryption for all the password traffic.
It consists of libraries that can be embedded into different standalone applications.
It provides the server as a separate program for a client/server networked environment.
Cons
Different members are unable to fix bugs and craft patches.
Users feel that MySQL no longer falls under the category of a free OS.
It’s no longer community driven.
It lags behind others due to its slow updates.
SQLite
SQLite is supposedly one of the most widely deployed databases in the world. It was developed in 2000 and, since then, it has been used by companies like Facebook, Apple, Microsoft and Google. Each of its releases is carefully tested in order to ensure reliability. Even if there are any bugs, the developers of SQLite are quite honest about the potential shortcomings by providing bug lists and the chronologies of different code changes for every release.
Pros
It has no separate server process.
The file format used is cross-platform.
It has a compact library, which runs faster even with more memory.
All its transactions are ACID compliant.
Professional support is also available for this database.
Cons
It’s not recommended for:
Different client/server applications.
All high-volume websites.
High concurrency.
Large datasets.
MongoDB
MongoDB was developed in 2007 and is well-known as the ‘database for giant ideas.’ It was developed by the people behind ShopWiki, DoubleClick, and Gilt Group. MongoDB is also backed by a large group of popular investors such as The Goldman Sachs Group Inc., Fidelity Investments, and Intel Capital. Since its inception, MongoDB has been downloaded over 15 million times and is supported by more than 1,000 partners. All its partners are dedicated to keeping this free and open source solution’s code and database simple and natural.
Pros
It has an encrypted storage engine.
It enables validation of documents.
Common use cases are mobile apps, catalogues, etc.
It has real-time apps with an in-memory storage engine (beta).
It reduces the time between primary failure and recovery.
Cons
It doesn’t fit applications which need complex transactions.
It’s not a drop-in replacement for different legacy applications.
It’s a young solution—its software changes and evolves quickly.
MariaDB
MariaDB has been developed by the original developers of MySQL. It is widely used by tech giants like Facebook, Wikipedia and even Google. It’s a database server that offers drop-in replacement functionality for MySQL. Security is one of the topmost concerns and priorities for MariaDB developers, and in each of its releases, the developers also merge in all of MySQL’s security patches, even enhancing them if required.
Pros
It has high scalability with easier integration.
It provides real-time access to data.
It has the maximum core functionalities of MySQL (MariaDB is an alternative for MySQL).
It has alternate storage engines, patches and server optimisations.
Cons
Password complexity plugin is missing.
It does not support the Memcached interface.
It has no optimiser trace.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.