CI/CD Pipeline: Understanding What it is and Why it Matters

The cloud computing explosion has led to the development of software programs and applications at an exponential rate. The ability to deliver features faster is now a competitive edge.
To achieve this your DevOps teams, structure & ecosystem should be well-oiled. Therefore it is critical to understand how to build an ideal CI/CD pipeline that will help to deliver features at a rapid pace.
Through this blog, we shall be exploring important cloud concepts, execution playbooks, and best practices of setting up CI/CD pipelines on public cloud environments like AWS, Azure, GCP, or even hybrid & multi-cloud environments.
HERE’S A BIRD’S EYE VIEW OF WHAT AN IDEAL CI/CD PIPELINE LOOKS LIKE
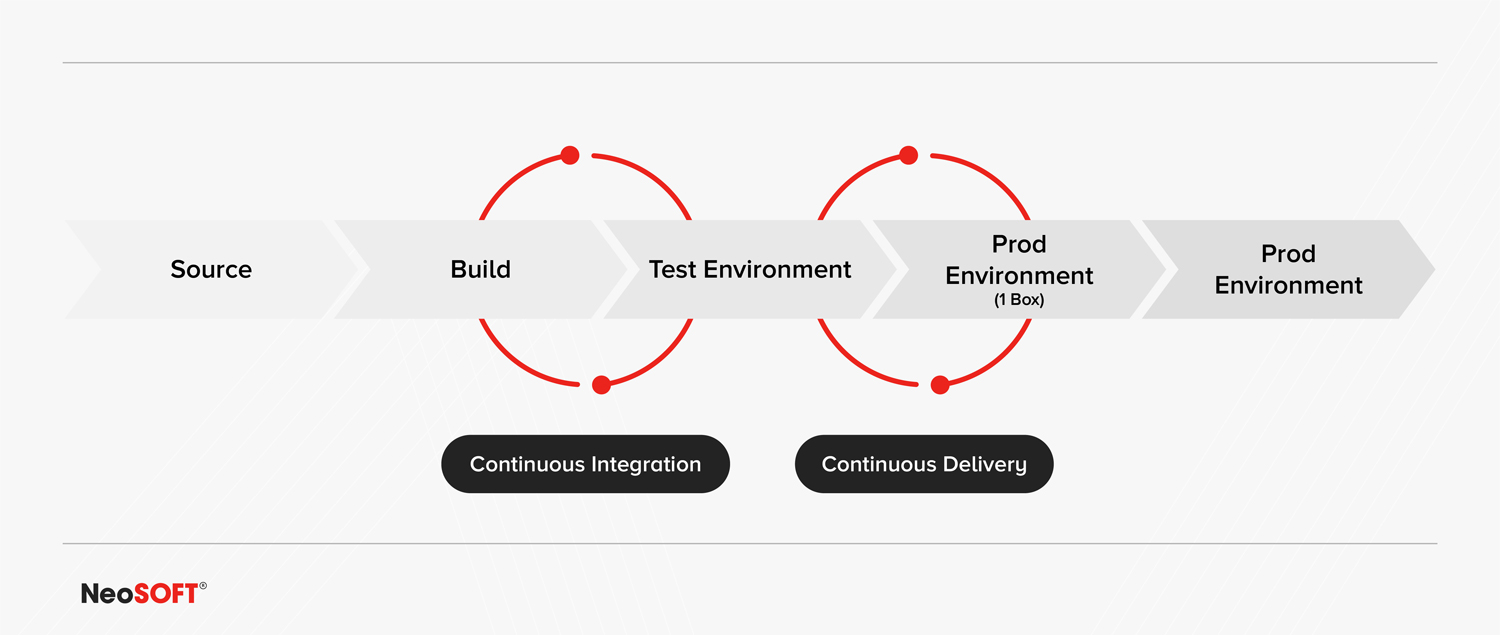
Let’s take a closer look at what each stage of the CI/CD involves:
Source Code:
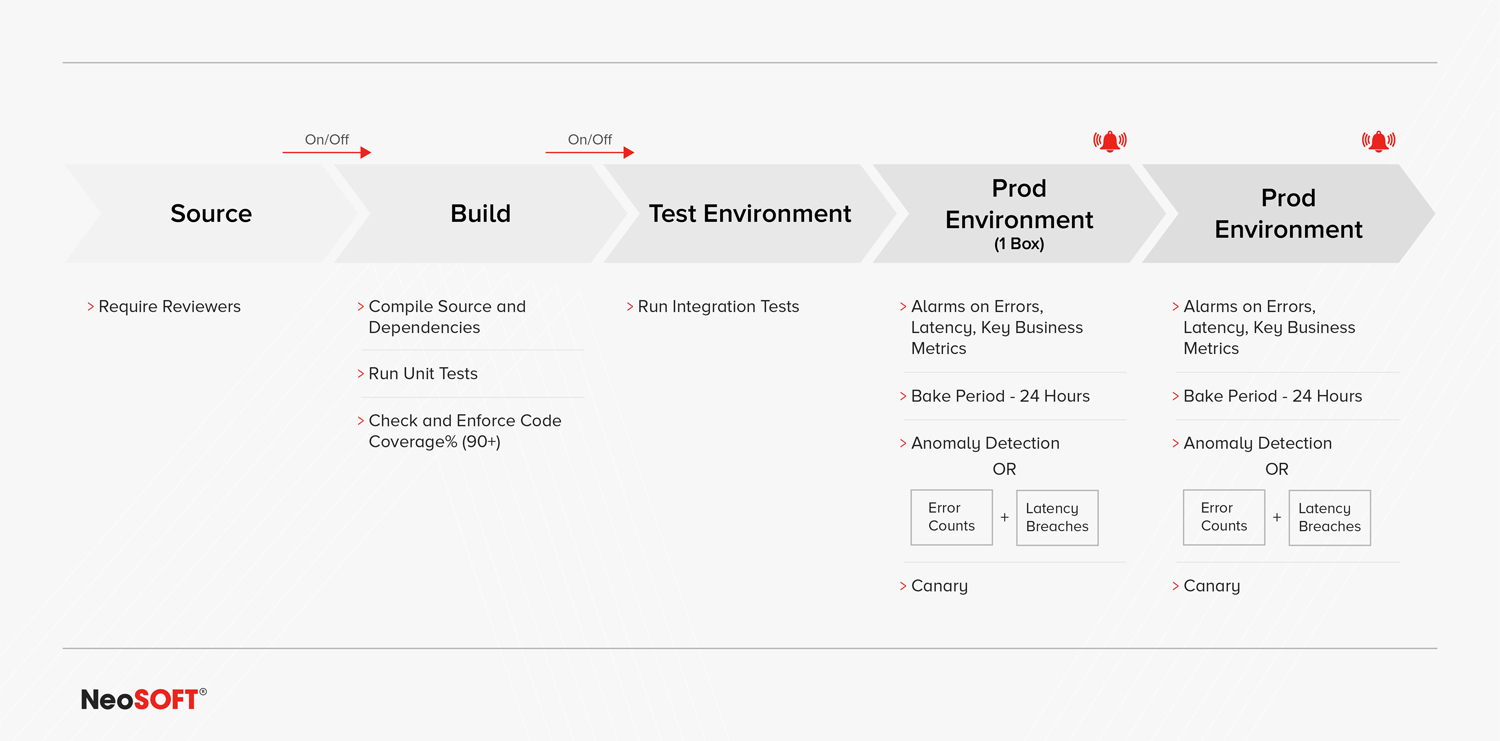
This is the starting point of any CI/CD pipeline. This is where all the packages and dependencies relevant to the application being developed are categorized and stored. At this stage, it is vital to have a mechanism that offers access to some reviewers in the project. This prevents developers from randomly merging bits of code into the source code. It is the reviewer’s job to approve any pull requests in order to progress the code into the next stage. Although this involves leveraging several different technologies, it certainly pays off in the long run.
Build:
Once a change has been committed to the source and approved by the reviewers, it automatically progresses to the Build stage.
1) Compile Source and Dependencies The first step in this stage is pretty straightforward, developers must simply compile the source code along with all its different dependencies.
2) Unit Tests This involves conducting a high coverage of unit tests. Currently, many tools show whether or not a line of code is being tested. To build an ideal CI/CD pipeline, the goal is to essentially commit source code into the build stage with the confidence that it will be caught in one of the later steps of the process. However, if high coverage unit tests are not conducted on the source code then it will progress directly into the next stage, leading to errors and requiring the developer to roll back to a previous version which is often a painful process. This makes it crucial to run a high coverage level of unit tests to be certain that the application is running and functioning correctly.
3) Check and Enforce Code Coverage (90%+) This ties into the testing frameworks above, however, it deals with the output code coverage percent related to a specific commit. Ideally, developers want to achieve a minimum of 90% and any subsequent commit should not fall below this threshold. The goal should be to achieve an increasing percentage for any future commits – the higher the better.
Test Environment:
This is the first environment the code enters. This is where the changes made to the code are tested and confirmed that they’re ready for the next stage, which is something closer to the production stage.
1) Integration Tests The primary thing to do as a prerequisite is to run integration tests. Although there are different interpretations of what exactly constitutes an integration test and how they compare to functional tests. To avoid this confusion, it is important to outline exactly what is meant when using the term.
In this case, let’s assume there is an integration test that executes a ‘create order’ API with an expected input. This should be immediately followed with a ‘get order’ API and checked to see if the order contains all the elements expected of it. If it does not, then there is something wrong. If it does then the pipeline is working as intended – congratulations.
Integration tests also analyze the behavior of the application in terms of business logic. For instance, if the developer inputs a ‘create order’ API and there’s a business rule within the application that prevents the creation of an order where the dollar value is above 10,000 dollars; an integration test must be performed to check that the application adheres to that benchmark as an expected business rule. In this stage, it is not uncommon to conduct around 50-100 integration tests depending on the size of the project, but the focus of this stage should mainly revolve around testing the core functionality of the APIs and checking to see if they are working as expected.
2) On/Off Switches At this point, let’s backtrack a little to include an important mechanism that must be used between the source code and build stage, as well as between the build and test stage. This mechanism is a simple on/off switch allowing the developer to enable or disable the flow of code at any point. This is a great technique for preventing source code that isn’t necessary to build right away from entering the build or test stage or maybe preventing code from interfering with something that is already being tested in the pipeline. This ‘switch’ enables developers to control exactly what gets promoted to the next stage of the pipeline.
If there are dependencies on any of the APIs, it is vital to conduct testing on those as well. For instance, if the ‘create order’ API is dependent on a customer profile service; it should be tested and checked to ensure that the customer profile service is receiving the expected information. This tests the end-to-end workflows of the entire system and offers added confidence to all the core APIs and core logic used in the pipeline, ensuring they are working as expected. It is important to note that developers will spend most of their time in this stage of the pipeline.
ON/OFF SWITCHES TO CONTROL CODE FLOW

Production:
The next stage after testing is usually the production stage. However, moving directly from testing to a production environment is usually only viable for small to medium organizations where only a couple of environments are used at the highest. But the larger an organization gets, the more environments they might need. This leads to difficulties in maintaining consistency and quality of code throughout the environment. To manage this, it is better for code to move from the testing stage to a pre-production stage and then move to a production stage. This becomes useful when there are many different developers testing things at different times like QA or a new specific feature is being tested. The pre-production environment allows developers to create a separate branch or additional environments for conducting a specific test.
This pre-production environment will be known as ‘Prod 1 Box’ for the rest of this article.
Pre-Production: (Prod 1Box)
A key aspect to remember when moving code from the testing environment is to ensure it does not cause a bad change to the main production environment where all the hosts are situated and where all the traffic is going to occur for the customer. The Prod 1 Box represents a fraction of the production traffic – ideally around less than 10% of total production traffic. This allows developers to detect when anything goes wrong while pushing code such as if the latency is really high. This will trigger the alarms, alerting the developers that a bad deployment is occurring and allowing them to roll back that particular change instantly.
The purpose of the Prod 1 Box is simple. If the code moves directly from the testing stage to the production stage and results in bad deployment, it would result in rolling back all the other hosts using the environment as well which is very tedious and time-consuming. But instead, if a bad deployment occurs in the Prod 1 Box, only one host is needed to be rolled back. This is a pretty straightforward process and extremely quick as well. The developer is only required to disable that particular host and the previous version of the code will be reverted to in the production environment without any harm and changes. Although simple in concept, the Prod 1 Box is a very powerful tool for developers as it offers an extra layer of safety when they introduce any changes to the pipeline before it hits the production stage.
1) Rollback Alarms When promoting code from the test stage to the production stage, several things can go wrong in the deployment. It can result in:
- An elevated number of errors
- Latency spikes
- Faltering key business metrics
- Various abnormal and expected patterns
This makes it crucial to incorporate the concept of alarms into the production environment – specifically rollback alarms. Rollback alarms are a type of alarm that monitors a particular environment and is integrated during the deployment process. It allows developers to monitor specific metrics of a particular deployment and that particular version of the software for issues like latency errors or if key business metrics are falling below a certain threshold. The rollback alarm is an indicator that alerts the developer to roll back the change to a previous version. In an ideal CI/CD pipeline these configured metrics should be monitored directly and the rollback initiated automatically. The automatic rollback must be baked into the system and triggered whenever it determines any of these metrics exceed or fall below the expected threshold.
2) Bake Period The Bake Period is more of a confidence-building step that allows developers to check for anomalies. The ideal duration of a Bake Period should be around 24 hours, but it isn’t uncommon for developers to keep the Bake Period to around 12 hours or even 6 hours during a high volume time frame.
Quite often when a change is introduced to an environment, errors might not pop up right away. Errors and latency spikes might be delayed, unexpected behavior of APIs or a certain code flow of APIs doesn’t occur until a certain system calls it, etc. This is why the Bake Period is important. It allows developers to be confident with the changes they’ve introduced. Once the code has sat for the set period and nothing abnormal has occurred, it is safe to move the code onto the next stage.
3) Anomaly Detection or Error Counts and Latency Breaches During the Bake period, developers can use anomaly detection tools to detect issues however that is an expensive endeavor for most organizations and often is an overkill solution. Another effective option, similar to the one used earlier, is to simply monitor the error counts and latency breaches over a set period. If the sum of the issues detected exceeds a certain threshold then the developer should roll back to a version of the code flow that was working.
4) Canary A canary tests the production workflow consistently with expected input and expected outcome. Let’s consider the ‘create order’ API we used earlier. In the integration test environment, the developer should set up a canary on that API along with a ‘cron job’ that triggers every minute.
The cron job should be given the function of monitoring the create order API with expected input and hardcoded with an expected output. The cron job must continually call or check on that API every minute. This would allow the developer to immediately know when this API begins failing or if the API output results in an error, notifying that something wrong has occurred within the system.
The concept of the canary must be integrated within the Bake Period, the key alarms as well the key metrics. All of which ultimately links back to the rollback alarm which reverts the pipeline to a previous software version that was assumed to be working perfectly.
Main Production:
When everything is functioning as expected within the Prod 1 Box, the code can be moved on to the next stage which is the main production environment. For instance, if the Prod 1 Box was hosting 10% of the traffic, then the main production environment would be hosting the remaining 90% of that traffic. All the elements and metrics used within the Prod 1 Box such as rollback alarms, Bake Period, anomaly detection or error count and latency breaches, and canaries, must be included in the stage exactly as they were in the Prod 1 Box with the same checks, except on a much larger scale.
The main issue most developers face is – ‘how is 10% of traffic supposed to be directed to one host while 90% goes to another host?’. While there are several ways of accomplishing this task, the easiest is to transfer it at the DNS level. Using DNS weights, developers can shift a certain percentage of traffic to a particular URL and the rest to another URL. The process might vary depending on the technology being used but DNS is the most common one that developers usually prefer to use.
DETAILED IDEAL CI/CD PIPELINE
Summary
The ultimate goal of an ideal CI/CD pipeline is to enable teams to generate quick, reliable, accurate, and comprehensive feedback from their SDLC. Regardless of the tools and configuration of the CI/CD pipeline, the focus should be to optimize and automate the software development process.
Let’s go Over the key Points Covered One More Time. These are the key Concepts And Elements that Make up an Ideal CI/CD Pipeline:
- The Source Code is where all the packages and dependencies are categorized and stored. It involves the addition of reviewers for the curation of code before it gets shifted to the next stage.
- Build steps involve compiling code, unit tests, as well as checking and enforcing code coverage.
- The Test Environment deals with integration testing and the creation of on/off switches.
- The Prod 1 Box serves as the soft testing environment for production for a portion of the traffic.
- The Main Production environment serves the remainder of the traffic
NeoSOFT’s DevOps services are geared towards delivering our signature exceptional quality and boosting efficiency wherever you are in your DevOps journey. Whether you want to build a CI/CD pipeline from scratch, or your CI/CD pipeline is ineffective and not delivering the required results, or if your CI/CD pipeline is in development but needs to be accelerated; our robust and signature engineering solutions will enable your organization to
- Scale rapidly across locations and geographies,
- Quicker delivery turnaround,
- Accelerate DevOps implementation across tools.
NEOSOFT’S DEVOPS SERVICES IMPACT ON ORGANIZATIONS

Solving Problems in the Real World
Over the past few years, we’ve applied the best practices mentioned in this article.
Organizations often find themselves requiring assistance at different stages in the DevOps journey; some wish to develop an entirely new DevOps approach, while others start by exploring how their existing systems and processes can be enhanced. As their products evolve and take on new characteristics, organizations need to re-imagine their DevOps processes and ensure that these changes aren’t affecting their efficiencies or hampering the quality of their product.
DevOps helps eCommerce Players to Release Features Faster
When it comes to eCommerce, DevOps is instrumental for increasing overall productivity, managing scale & deploying new and innovative features much faster.
For a global e-commerce platform with millions of daily visitors, NeoSOFT built their CI/CD pipeline. Huge computational resources were made to work efficiently, giving a pleasing online customer experience. The infrastructure was able to carry out a number of mission-critical functions with substantial savings resulting in both: time and money.
With savings up to 40% on computing & storage resources matched with an enhanced developer throughput, an ideal CI/CD pipeline is critical to the eCommerce industry.
Robust CI/CD Pipelines are Driving Phenomenal CX in the BFSI Sector
DevOps’ ability to meet the continually growing user needs with the need to rapidly deploy new features has facilitated its broader adoption across the BFSI industry with varying maturity levels.
When executing a digital transformation project for a leading bank, NeoSOFT upgraded the entire infrastructure with an objective to achieve continuous delivery. The introduction of emerging technologies like Kubernetes into the journey enabled the institution to move at startup speed, driving the GTM 10x faster rate.
As technology leaders in the BFSI segment look to compete through digital capabilities, DevOps & CI/CD pipelines start to form their cornerstone of innovation.
A well-oiled DevOps team, structure, and ecosystem can be the difference-maker in driving business benefits and leveraging technology as your competitive edge.
Begin your DevOps Journey Today!
Speak to us —let’s Build.